publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
-
 HandX: Scaling Bimanual Motion and Interaction GenerationZimu Zhang*, Yucheng Zhang*, Xiyan Xu, Ziyin Wang, Sirui Xu, Kai Zhou, Bing Zhou, Chuan Guo, Jian Wang, Yu-Xiong Wang, and Liang-Yan GuiIn CVPR, 2026
HandX: Scaling Bimanual Motion and Interaction GenerationZimu Zhang*, Yucheng Zhang*, Xiyan Xu, Ziyin Wang, Sirui Xu, Kai Zhou, Bing Zhou, Chuan Guo, Jian Wang, Yu-Xiong Wang, and Liang-Yan GuiIn CVPR, 2026Synthesizing human motion has advanced rapidly, yet realistic hand motion and bimanual interaction remain underexplored. Whole-body models often miss the fine-grained cues that drive dexterous behavior, finger articulation, contact timing, and inter-hand coordination, and existing resources lack high-fidelity bimanual sequences that capture nuanced finger dynamics and collaboration. To fill this gap, we collect a new dataset targeting these underrepresented aspects. For scalable annotation, we introduce a decoupled paradigm that extracts representative motion features, e.g., contact events and finger flexion, and then leverages reasoning from large language model to produce fine-grained, semantically rich descriptions aligned with these features. Building on the resulting data and annotations, we benchmark diffusion and autoregressive models with versatile conditioning modes. Experiments demonstrate high-quality dexterous motion generation, supported by our newly proposed hand-focused metrics. We further observe clear scaling trends: larger models trained on larger, higher-quality datasets produce more semantically coherent bimanual motions. All data will be released to support future research.
@inproceedings{zhang2026handx, title = {HandX: Scaling Bimanual Motion and Interaction Generation}, author = {Zhang*, Zimu and Zhang*, Yucheng and Xu, Xiyan and Wang, Ziyin and Xu, Sirui and Zhou, Kai and Zhou, Bing and Guo, Chuan and Wang, Jian and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {CVPR}, year = {2026}, }

2025
-
 InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction GenerationSirui Xu*, Dongting Li*, Yucheng Zhang*, Xiyan Xu*, Qi Long*, Ziyin Wang*, Yunzhi Lu, Shuchang Dong, Hezi Jiang, Akshat Gupta, Yu-Xiong Wang, and Liang-Yan GuiIn CVPR, 2025
InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction GenerationSirui Xu*, Dongting Li*, Yucheng Zhang*, Xiyan Xu*, Qi Long*, Ziyin Wang*, Yunzhi Lu, Shuchang Dong, Hezi Jiang, Akshat Gupta, Yu-Xiong Wang, and Liang-Yan GuiIn CVPR, 2025While large-scale human motion capture datasets have advanced human motion generation, modeling and generating dynamic 3D human-object interactions (HOIs) remains challenging due to dataset limitations. These datasets often lack extensive, high-quality text-interaction pair data and exhibit artifacts such as contact penetration, floating, and incorrect hand motions. To address these issues, we introduce InterAct, a large-scale 3D HOI benchmark with key contributions in both dataset and methodology. First, we consolidate 21.81 hours of HOI data from diverse sources, standardizing and enriching them with detailed textual annotations. Second, we propose a unified optimization framework that enhances data quality by minimizing artifacts and restoring hand motions. Leveraging the insight of contact invariance, we preserve human-object relationships while introducing motion variations, thereby expanding the dataset to 30.70 hours. Third, we introduce six tasks to benchmark existing methods and develop a unified HOI generative model based on multi-task learning that achieves state-of-the-art results. Extensive experiments validate the utility of our dataset as a foundational resource for advancing 3D human-object interaction generation. The dataset will be publicly accessible to support further research in the field.
@inproceedings{xu2025interact, title = {InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction Generation}, author = {Xu*, Sirui and Li*, Dongting and Zhang*, Yucheng and Xu*, Xiyan and Long*, Qi and Wang*, Ziyin and Lu, Yunzhi and Dong, Shuchang and Jiang, Hezi and Gupta, Akshat and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {CVPR}, year = {2025}, } -
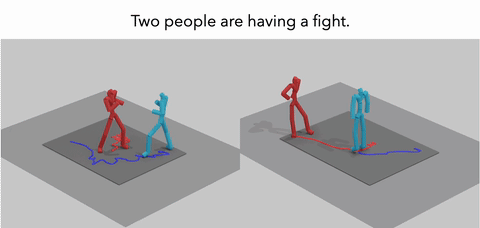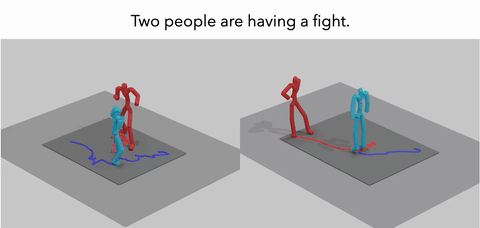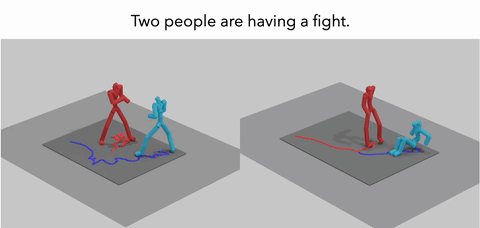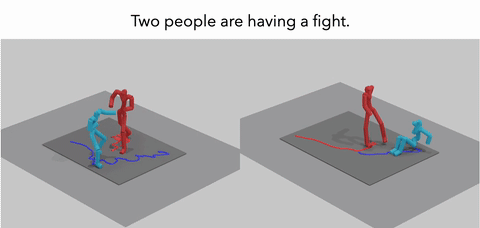 MoReact: Generating Reactive Motion from Textual DescriptionsXiyan Xu, Sirui Xu, Yu-Xiong Wang, and Liang-Yan GuiIn TMLR, 2025
MoReact: Generating Reactive Motion from Textual DescriptionsXiyan Xu, Sirui Xu, Yu-Xiong Wang, and Liang-Yan GuiIn TMLR, 2025Modeling and generating human reactions poses a significant challenge with broad applications for computer vision and human-computer interaction. Existing methods either treat multiple individuals as a single entity, directly generating interactions, or rely solely on one person’s motion to generate the other’s reaction, failing to integrate the rich semantic information that underpins human interactions. Yet, these methods often fall short in adaptive responsiveness, i.e., the ability to accurately respond to diverse and dynamic interaction scenarios. Recognizing this gap, our work introduces an approach tailored to address the limitations of existing models by focusing on text-driven human reaction generation. Our model specifically generates realistic motion sequences for individuals that responding to the other’s actions based on a descriptive text of the interaction scenario. The goal is to produce motion sequences that not only complement the opponent’s movements but also semantically fit the described interactions. To achieve this, we present MoReact, a diffusion-based method designed to disentangle the generation of global trajectories and local motions sequentially. This approach stems from the observation that generating global trajectories first is crucial for guiding local motion, ensuring better alignment with given action and text. Furthermore, we introduce a novel interaction loss to enhance the realism of generated close interactions. Our experiments, utilizing data adapted from a two-person motion dataset, demonstrate the efficacy of our approach for this novel task, which is capable of producing realistic, diverse, and controllable reactions that not only closely match the movements of the counterpart but also adhere to the textual guidance.
@inproceedings{xu2025moreact, title = {MoReact: Generating Reactive Motion from Textual Descriptions}, author = {Xu, Xiyan and Xu, Sirui and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {TMLR}, year = {2025}, }


2023
-
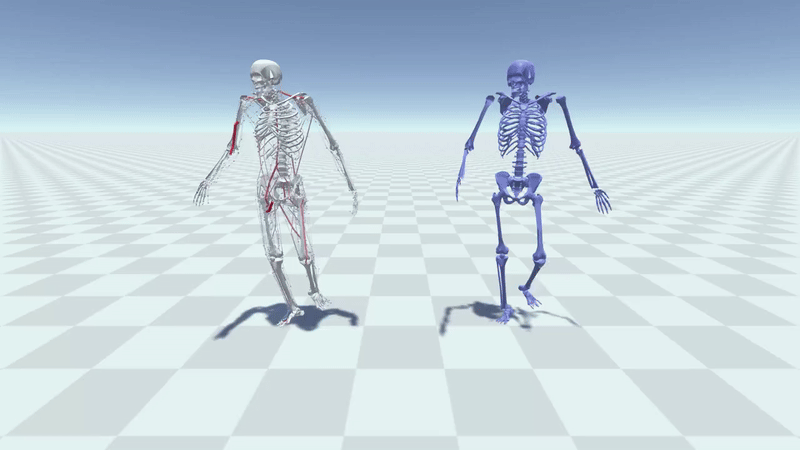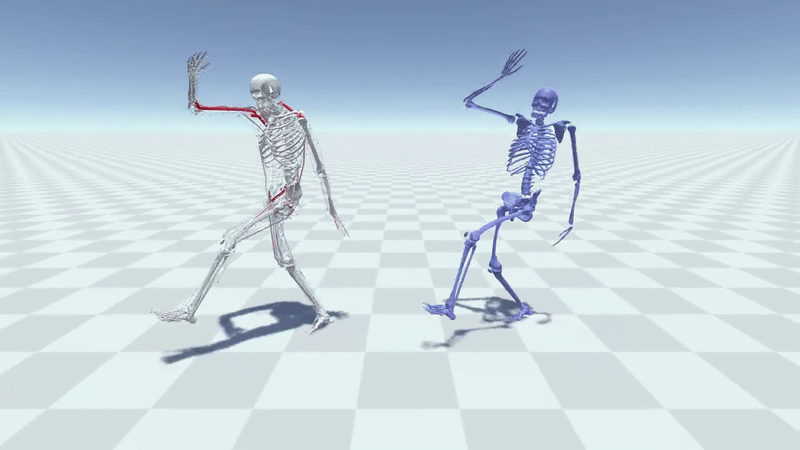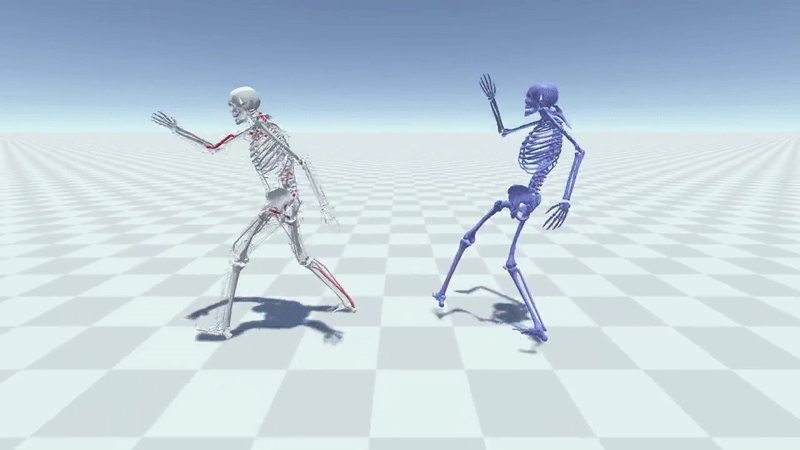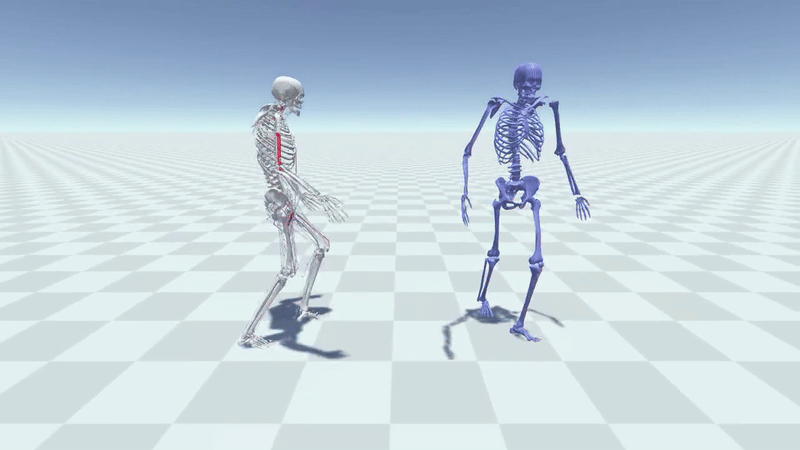 MuscleVAE: Model-Based Controllers of Muscle-Actuated CharactersYusen Feng, Xiyan Xu, and Libin LiuIn SIGGRAPH Asia 2023 Conference Papers, 2023
MuscleVAE: Model-Based Controllers of Muscle-Actuated CharactersYusen Feng, Xiyan Xu, and Libin LiuIn SIGGRAPH Asia 2023 Conference Papers, 2023In this paper, we present a simulation and control framework for generating biomechanically plausible motion for muscle-actuated characters. We incorporate a fatigue dynamics model, the 3CC-r model, into the widely-adopted Hill-type muscle model to simulate the development and recovery of fatigue in muscles, which creates a natural evolution of motion style caused by the accumulation of fatigue from prolonged activities. To address the challenging problem of controlling a musculoskeletal system with high degrees of freedom, we propose a novel muscle-space control strategy based on PD control. Our simulation and control framework facilitates the training of a generative model for muscle-based motion control, which we refer to as MuscleVAE. By leveraging the variational autoencoders (VAEs), MuscleVAE is capable of learning a rich and flexible latent representation of skills from a large unstructured motion dataset, encoding not only motion features but also muscle control and fatigue properties. We demonstrate that the MuscleVAE model can be efficiently trained using a model-based approach, resulting in the production of high-fidelity motions and enabling a variety of downstream tasks.
@inproceedings{feng2023musclevae, title = {MuscleVAE: Model-Based Controllers of Muscle-Actuated Characters}, author = {Feng, Yusen and Xu, Xiyan and Liu, Libin}, booktitle = {SIGGRAPH Asia 2023 Conference Papers}, pages = {1--11}, year = {2023}, }
